WeAvatar 及耗子通行证是我所维护的核心业务,对稳定性要求极高,由于最近 2 个月的 3 次中断均由机房造成,因此有必要研究搭建一套多活机制,确保在出现单机房故障时不至于中断服务。
这篇文章只关注如何搭建主从 TiDB 集群实现多活,其余多活机制的实现将在其他文章中讨论。
开始操作之前,需确保以下几点操作均已完成:
- 主从集群的服务器时间需同步一下 (可以使用 NTP 等完成)
- 如果表很大,需提前在从集群导入完整备份,因为 TiDB 默认的 GC 时间是 10 分钟,也就是说从主集群备份到运行好 TiCDC 必须在 10 分钟内完成,否则会报错
[tikv:9006]GC life time is shorter than transaction duration, transaction starts at xx, GC safe point is yy,因此需要先导入完整备份再增量导入差异部分到 10 分钟以内。当然也可以通过调整延长 GC 时间,自选。
准备完成后即可开始,下面均为本人实际操作,部分数据经过脱敏处理:
一、建立 TiCDC 配置文件
在主集群建立一份 TiCDC 配置文件 tidb-cdc.toml,内容如下:
# 指定该 Changefeed 在 Capture Server 中内存配额的上限。对于超额使用部分,
# 会在运行中被 Go runtime 优先回收。默认值为 `1073741824`,即 1 GB 。
# memory-quota = 1073741824
# 指定配置文件中涉及的库名、表名是否为大小写敏感
# 该配置会同时影响 filter 和 sink 相关配置,默认为 true
case-sensitive = true
# 是否输出 old value,从 v4.0.5 开始支持,从 v5.0 开始默认为 true
enable-old-value = true
# 是否开启 Syncpoint 功能,从 v6.3.0 开始支持,该功能默认关闭。
# 从 v6.4.0 开始,使用 Syncpoint 功能需要同步任务拥有下游集群的 SYSTEM_VARIABLES_ADMIN 或者 SUPER 权限。
# 注意:该参数只有当下游为 TiDB 时,才会生效。
# enable-sync-point = false
# Syncpoint 功能对齐上下游 snapshot 的时间间隔
# 配置格式为 h m s,例如 "1h30m30s"
# 默认值为 10m,最小值为 30s
# 注意:该参数只有当下游为 TiDB 时,才会生效。
# sync-point-interval = "5m"
# Syncpoint 功能在下游表中保存的数据的时长,超过这个时间的数据会被清理
# 配置格式为 h m s,例如 "24h30m30s"
# 默认值为 24h
# 注意:该参数只有当下游为 TiDB 时,才会生效。
# sync-point-retention = "1h"
[mounter]
# mounter 解码 KV 数据的线程数,默认值为 16
# worker-num = 16
[filter]
# 忽略指定 start_ts 的事务
# ignore-txn-start-ts = [1, 2]
# 过滤器规则
# 过滤规则语法:https://docs.pingcap.com/zh/tidb/stable/table-filter#表库过滤语法
rules = ['aaa.*', 'bbb.*']
# 事件过滤器规则
# 事件过滤器的详细配置规则可参考:https://docs.pingcap.com/zh/tidb/stable/ticdc-filter
# 第一个事件过滤器规则
# [[filter.event-filters]]
# matcher = ["test.worker"] # matcher 是一个白名单,表示该过滤规则只应用于 test 库中的 worker 表
# ignore-event = ["insert"] # 过滤掉 insert 事件
# ignore-sql = ["^drop", "add column"] # 过滤掉以 "drop" 开头或者包含 "add column" 的 DDL
# ignore-delete-value-expr = "name = 'john'" # 过滤掉包含 name = 'john' 条件的 delete DML
# ignore-insert-value-expr = "id >= 100" # 过滤掉包含 id >= 100 条件的 insert DML
# ignore-update-old-value-expr = "age < 18" # 过滤掉旧值 age < 18 的 update DML
# ignore-update-new-value-expr = "gender = 'male'" # 过滤掉新值 gender = 'male' 的 update DML
# 第二个事件过滤器规则
# [[filter.event-filters]]
# matcher = ["test.fruit"] # 该事件过滤器只应用于 test.fruit 表
# ignore-event = ["drop table", "delete"] # 忽略 drop table 的 DDL 事件和 delete 类型的 DML 事件
# ignore-sql = ["^drop table", "alter table"] # 忽略以 drop table 开头的,或者包含 alter table 的 DDL 语句
# ignore-insert-value-expr = "price > 1000 and origin = 'no where'" # 忽略包含 price > 1000 和 origin = 'no where' 条件的 insert DML
[scheduler]
# 将表以 Region 为单位分配给多个 TiCDC 节点进行同步。
# 注意:该功能只在 Kafka changefeed 上生效,暂不支持 MySQL changefeed 。
# 默认为 "false"。设置为 "true" 以打开该功能。
enable-table-across-nodes = false
# enable-table-across-nodes 开启后,有两种分配模式
# 1. 按 Region 的数量分配,即每个 CDC 节点处理 region 的个数基本相等。当某个表 Region 个数大于 `region-threshold` 值时,会将表分配到多个节点处理。`region-threshold` 默认值为 10000 。
# region-threshold = 10000
# 2. 按写入的流量分配,即每个 CDC 节点处理 region 总修改行数基本相当。只有当表中每分钟修改行数超过 `write-key-threshold` 值时,该表才会生效。
# write-key-threshold = 30000
# 注意:
# `write-key-threshold` 参数默认值为 0,代表默认不会采用流量的分配模式。
# 两种方式配置一种即可生效,当 `region-threshold` 和 `write-key-threshold` 同时配置时,TiCDC 将优先采用按流量分配的模式,即 `write-key-threshold`。
[sink]
# 对于 MQ 类的 Sink,可以通过 dispatchers 配置 event 分发器
# 支持 partition 及 topic(从 v6.1 开始支持) 两种 event 分发器。二者的详细说明见下一节。
# matcher 的匹配语法和过滤器规则语法相同,matcher 匹配规则的详细说明见下一节。
# 注意:该参数只有当下游为消息队列时,才会生效。
# dispatchers = [
# {matcher = ['test1.*', 'test2.*'], topic = "Topic 表达式 1", partition = "ts" },
# {matcher = ['test3.*', 'test4.*'], topic = "Topic 表达式 2", partition = "index-value" },
# {matcher = ['test1.*', 'test5.*'], topic = "Topic 表达式 3", partition = "table"},
# {matcher = ['test6.*'], partition = "ts"}
# ]
# protocol 用于指定传递到下游的协议格式
# 当下游类型是 Kafka 时,支持 canal-json 、 avro 两种协议。
# 当下游类型是存储服务时,目前仅支持 canal-json 、 csv 两种协议。
# 注意:该参数只有当下游为 Kafka 或存储服务时,才会生效。
# protocol = "canal-json"
# 以下三个配置项仅在同步到存储服务的 sink 中使用,在 MQ 和 MySQL 类 sink 中无需设置。
# 换行符,用来分隔两个数据变更事件。默认值为空,表示使用 "\r\n" 作为换行符。
# terminator = ''
# 文件路径的日期分隔类型。可选类型有 `none`、`year`、`month` 和 `day`。默认值为 `day`,即按天分隔。详见 <https://docs.pingcap.com/zh/tidb/v7.1/ticdc-sink-to-cloud-storage#数据变更记录> 。
# 注意:该参数只有当下游为存储服务时,才会生效。
date-separator = 'day'
# 是否使用 partition 作为分隔字符串。默认值为 true,即一张表中各个 partition 的数据会分不同的目录来存储。建议保持该配置项为 true 以避免下游分区表可能丢数据的问题 <https://github.com/pingcap/tiflow/issues/8581> 。使用示例详见 <https://docs.pingcap.com/zh/tidb/v7.1/ticdc-sink-to-cloud-storage#数据变更记录> 。
# 注意:该参数只有当下游为存储服务时,才会生效。
enable-partition-separator = true
# Schema 注册表的 URL 。
# 注意:该参数只有当下游为消息队列时,才会生效。
# schema-registry = "http://localhost:80801/subjects/{subject-name}/versions/{version-number}/schema"
# 编码数据时所用编码器的线程数。
# 默认值为 16 。
# 注意:该参数只有当下游为消息队列时,才会生效。
# encoder-concurrency = 16
# 是否开启 Kafka Sink V2 。 Kafka Sink V2 内部使用 kafka-go 实现。
# 默认值为 false 。
# 注意:该参数只有当下游为消息队列时,才会生效。
# enable-kafka-sink-v2 = false
# 是否只向下游同步有内容更新的列。从 v7.1.0 开始支持。
# 默认值为 false 。
# 注意:该参数只有当下游为消息队列,并且使用 Open Protocol 或 Canal-JSON 时,才会生效。
# only-output-updated-columns = false
# 从 v6.5.0 开始,TiCDC 支持以 CSV 格式将数据变更记录保存至存储服务中,在 MQ 和 MySQL 类 sink 中无需设置。
# [sink.csv]
# 字段之间的分隔符。必须为 ASCII 字符,默认值为 `,`。
# delimiter = ','
# 用于包裹字段的引号字符。空值代表不使用引号字符。默认值为 `"`。
# quote = '"'
# CSV 中列为 NULL 时将以什么字符来表示。默认值为 `\N`。
# null = '\N'
# 是否在 CSV 行中包含 commit-ts 。默认值为 false 。
# include-commit-ts = false
# consistent 中的字段用于配置 Changefeed 的数据一致性。详细的信息,请参考 <https://docs.pingcap.com/tidb/stable/ticdc-sink-to-mysql#eventually-consistent-replication-in-disaster-scenarios> 。
# 注意:一致性相关参数只有当下游为数据库并且开启 redo log 功能时,才会生效。
[consistent]
# 数据一致性级别。默认值为 "none",可选值为 "none" 和 "eventual"。
# 设置为 "none" 时将关闭 redo log 。
level = "none"
# redo log 的最大日志大小,单位为 MB 。默认值为 64 。
max-log-size = 64
# 两次 redo log 刷新的时间间隔,单位为毫秒。默认值为 2000 。
flush-interval = 2000
# redo log 使用存储服务的 URI 。默认值为空。
storage = ""
# 是否将 redo log 存储到文件中。默认值为 false 。
use-file-backend = false
[integrity]
# 是否开启单行数据的 Checksum 校验功能,默认值为 "none",即不开启。可选值为 "none" 和 "correctness"。
integrity-check-level = "none"
# 当单行数据的 Checksum 校验失败时,Changefeed 打印错误行数据相关日志的级别。默认值为 "warn",可选值为 "warn" 和 "error"。
corruption-handle-level = "warn"
# 以下参数仅在下游为 Kafka 时生效。从 v7.1.1 开始支持。
[sink.kafka-config]
# Kafka SASL 认证机制。该参数默认值为空,表示不使用 SASL 认证。
sasl-mechanism = "OAUTHBEARER"
# Kafka SASL OAUTHBEARER 认证机制中的 client-id 。默认值为空。在使用该认证机制时,该参数必填。
sasl-oauth-client-id = "producer-kafka"
# Kafka SASL OAUTHBEARER 认证机制中的 client-secret 。默认值为空。需要 Base64 编码。在使用该认证机制时,该参数必填。
sasl-oauth-client-secret = "cHJvZHVjZXIta2Fma2E="
# Kafka SASL OAUTHBEARER 认证机制中的 token-url 用于获取 token 。默认值为空。在使用该认证机制时,该参数必填。
sasl-oauth-token-url = "http://127.0.0.1:4444/oauth2/token"
# Kafka SASL OAUTHBEARER 认证机制中的 scopes 。默认值为空。在使用该认证机制时,该参数可选填。
sasl-oauth-scopes = ["producer.kafka", "consumer.kafka"]
# Kafka SASL OAUTHBEARER 认证机制中的 grant-type 。默认值为 "client_credentials"。在使用该认证机制时,该参数可选填。
sasl-oauth-grant-type = "client_credentials"
# Kafka SASL OAUTHBEARER 认证机制中的 audience 。默认值为空。在使用该认证机制时,该参数可选填。
sasl-oauth-audience = "kafka"其中过滤器规则用于指定需要同步的数据库和表名,aaa.bbb 表示 aaa 数据库的 bbb 表,可以使用*号全选和! 号取反,更多过滤器语法可参考官方文档 TiCDC Changefeed 命令行参数和配置参数 | PingCAP 文档中心。
二、安装 TiCDC
在主集群上建立 scale-out.yml 文件如下:
cdc_servers:
- host: 127.x.x.x
port: 8300
deploy_dir: "/www/tidb/tidb-deploy/cdc-8300"
data_dir: "/www/tidb/tidb-data/cdc-8300"
log_dir: "/www/tidb/tidb-deploy/cdc-8300/log"
- host: 127.x.x.x
port: 8301
deploy_dir: "/www/tidb/tidb-deploy/cdc-8301"
data_dir: "/www/tidb/tidb-data/cdc-8301"
log_dir: "/www/tidb/tidb-deploy/cdc-8301/log"然后执行以下命令平滑扩容安装 TiCDC:
tiup cluster scale-out <cluster-name> scale-out.yml三、增量同步数据差到 10 分钟以内
TiDB 导出文件中有一个 metadata 文件,需确保里面的 Pos 时间戳在导入从集群完成以后仍小于主集群的 gc_safe_point 时间,否则无法继续操作。查询主集群的 gc_safe_point 可以通过下述命令:
tiup ctl:v7.3.0 pd service-gc-safepoint --pd http://127.x.x.x:2379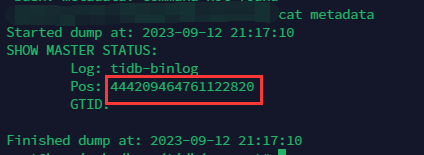
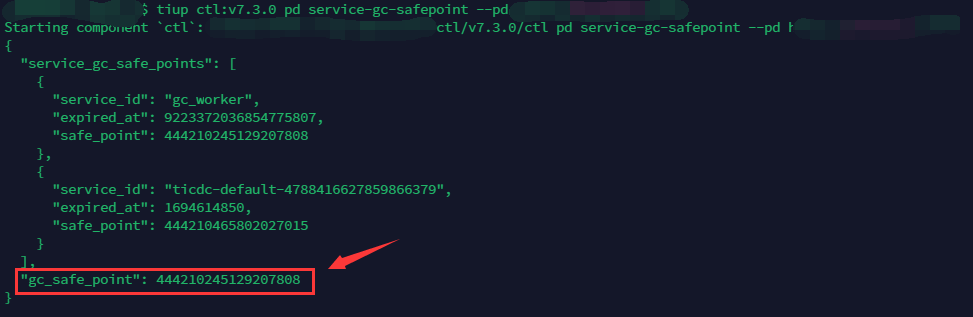
如果 ctl 没安装,请通过 tiup install ctl 安装之。
不断操作增量备份和导入,直到满足要求即可继续。
三、创建 TiCDC Changefeed 开始同步
TiCDC 安装完成即可创建 Changefeed 以开始同步过程,执行:
tiup cdc cli changefeed create --server=http://127.x.x.x:8300 --sink-uri="mysql://root:password@x.x.x.x:xxxx/" --changefeed-id="sync-to-xxx" --start-ts=444208984998543364 --config=tidb-cdc.toml其中:
server为任意 TiCDC 节点的地址sink-uri中需输入从集群用户名和密码以及地址changefeed-id格式必须为 xxx-xxx-xxx 这种,不指定会自动生产一个 UUIDstart-ts即为最后备份文件 metadata 中的 Pos 值config指定前面配置文件的路径
运行后如果没有报错输出,同步即已经开始。

可通过下述命令查询同步状态:
tiup cdc cli changefeed list --server=http://127.x.x.x:8300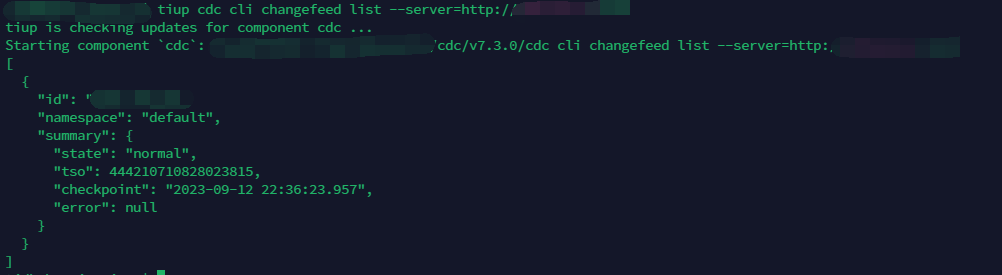



文章评论
学习!